__device__ __forceinline__ unsigned int bfe(unsigned int source, unsigned int bitIndex) {
unsigned int bit;
asm volatile("bfe.u32 %0, %1, %2, %3;" : "=r"(bit) : "r"((unsigned int) source), "r"(bitIndex), "r"(1));
return bit;
}
上面这段代码。主要用于从 32bit 中抽取出一个特定的 bit (Bit Field Extract, BFE). 其中有 4 个操作数的位置需要填充,%1 是指 source,%2是指指定的 index (0~31), %3是抽取的长度,这里是 1.
再配合上__forceinline__的强制优化,这一步实际上可能就一个 cycle 就能完成。
// 比较器,用于比较和交换两个值
template <typename T>
__device__ __forceinline__ T comparator(
const T value,
const int stride,
const int direction
) {
const T other = __shfl_xor_sync(0xffffffff, value, stride);
bool swap = (value > other) == direction;
return swap ? other : value;
}
上面这段代码,采用了及其高效的方式进行 swap中两个线程之间进行数据交换+比较。
第一行代码: __shfl_xor_sync(0xffffffff, value, stride) , 采用了 Warp 内的原语进行操作含义是:0xffffffff 这里是 32 个 1的 16 进制写法, 含义是 32 个线程都参与计算(这里注意, Warp 中每个线程都必须参与!否则会死锁)然后,value 是本线程拿到的值,stride 用来找到另一个线程,然后返回出来的值即为其他线程的值。关于这部分的进一步理解,可以参考下面的文章。
[!info] CUDA 知识点:线程束洗牌函数 | CUDA
CUDA 中的线程束内基本函数包括: 线程束表决函数(warp vote functions) 线程束匹配函数(warp match functions) 线程束洗牌函数(warp shuffle functions) 线程束矩阵函数(warp matrix functions) 其中,线程束匹配函数和线程束矩阵函数都只能在 Volta 及更高架构的 GPU 中使用。本文主要介绍线程束洗牌函数
第二行代码:bool swap = (value > other) == direction; ,用一个 bool 类型的 swap 变量来表示是否要跟对面的线程来交换数据。是否交换,由右边的判断来决定。比如 direction = 1 代表升序的话,那么当前值大于对面的值,两者相等,从而swap 值为 true,触发交换(隐含逻辑:当前线程的 ID 要比对面线程的 ID 要大)
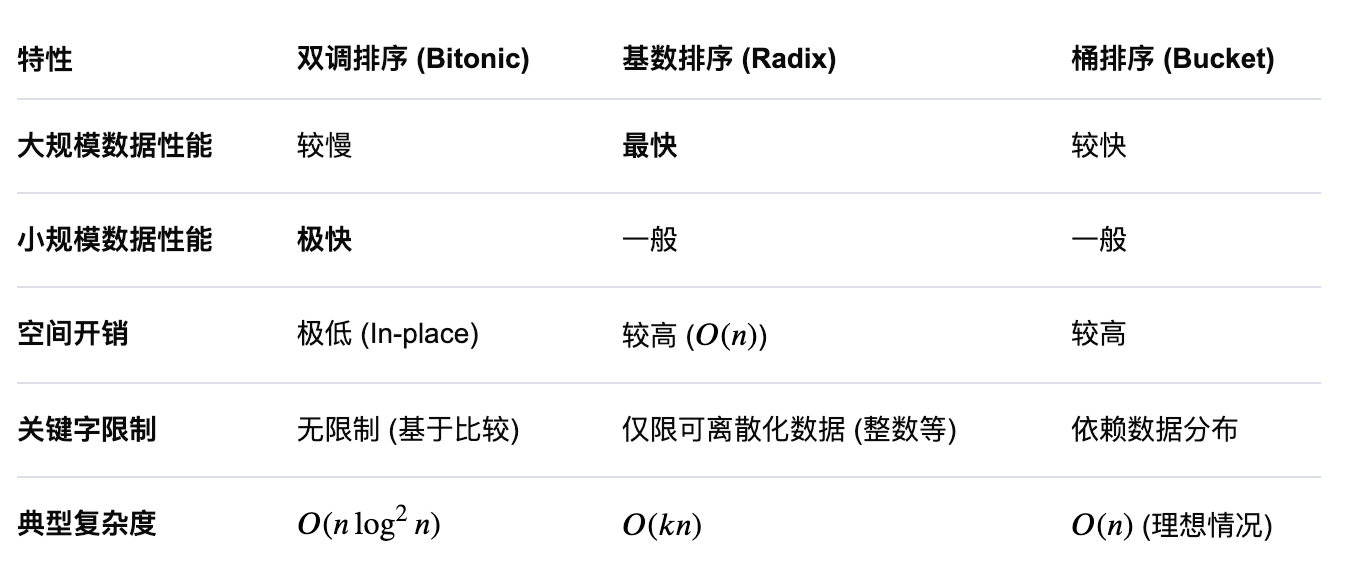
首先,我们得解释一下,什么叫双调排序,以及它和其他排序方式的对比,从而弄明白为什么在这里的排序方式使用这个排序算法。
image 3.png
可以看到,双调排序的特点是:不依赖数据的特征(浮点可用),且小规模时极快。非常符合这里的 MoE 场景里的选 Top-K 个浮点数分数的 case。具体的抽象实现,可以参考洛谷的一篇解释:
https://www.luogu.com/article/arg8ui9m
template <typename T>
__device__ __forceinline__ void warpSort_desend32(
T & threadValue,
const unsigned int laneId,
const unsigned int length = 32 // 默认排序8个数
) {
// 对于8个数的排序,我们只需要前3步
threadValue = comparator(threadValue, 1, bfe(laneId, 1) ^ bfe(laneId, 0));
// 排序长度为4的序列
threadValue = comparator(threadValue, 2, bfe(laneId, 2) ^ bfe(laneId, 1));
threadValue = comparator(threadValue, 1, bfe(laneId, 2) ^ bfe(laneId, 0));
// 排序长度为8的序列
threadValue = comparator(threadValue, 4, bfe(laneId, 3) ^ bfe(laneId, 2));
threadValue = comparator(threadValue, 2, bfe(laneId, 3) ^ bfe(laneId, 1));
threadValue = comparator(threadValue, 1, bfe(laneId, 3) ^ bfe(laneId, 0));
// 排序长度为16的序列
threadValue = comparator(threadValue, 8, bfe(laneId, 4) ^ bfe(laneId, 3));
threadValue = comparator(threadValue, 4, bfe(laneId, 4) ^ bfe(laneId, 2));
threadValue = comparator(threadValue, 2, bfe(laneId, 4) ^ bfe(laneId, 1));
threadValue = comparator(threadValue, 1, bfe(laneId, 4) ^ bfe(laneId, 0));
// 排序长度为32的序列
threadValue = comparator(threadValue, 16, bfe(laneId, 4));
threadValue = comparator(threadValue, 8, bfe(laneId, 3));
threadValue = comparator(threadValue, 4, bfe(laneId, 2));
threadValue = comparator(threadValue, 2, bfe(laneId, 1));
threadValue = comparator(threadValue, 1, bfe(laneId, 0));
}
简单理解,转换成代码后,其实就是**分治+递归思想;**从一对 pair 的线程开始对比,然后 merge 成更大的序列,merge 后短暂失序,继续递归对比即可。至于 bfe(laneId ,x) ^ bfe(laneID,y),用于控制一个组内的线程用一个方向(升序/降序)。